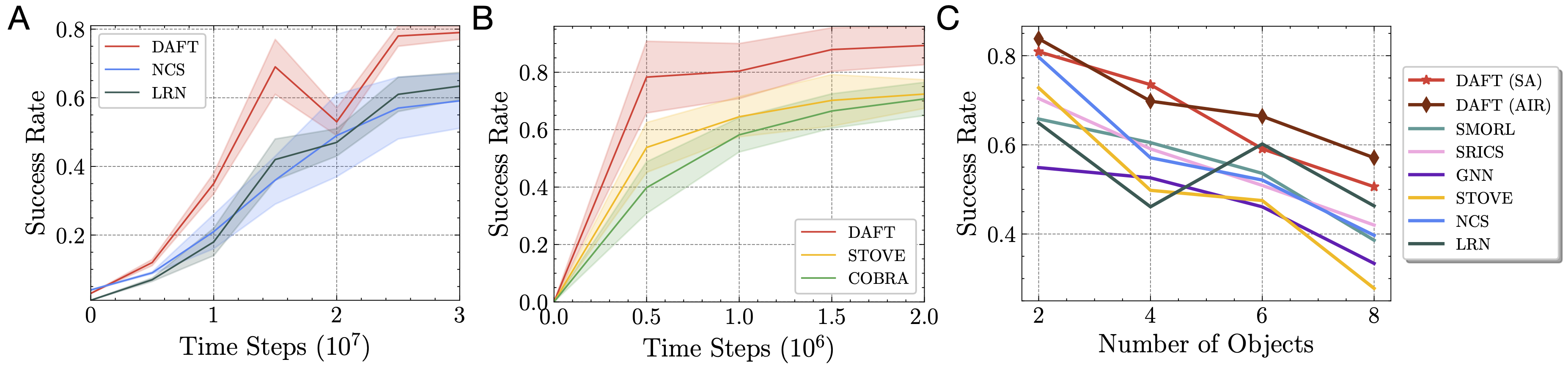
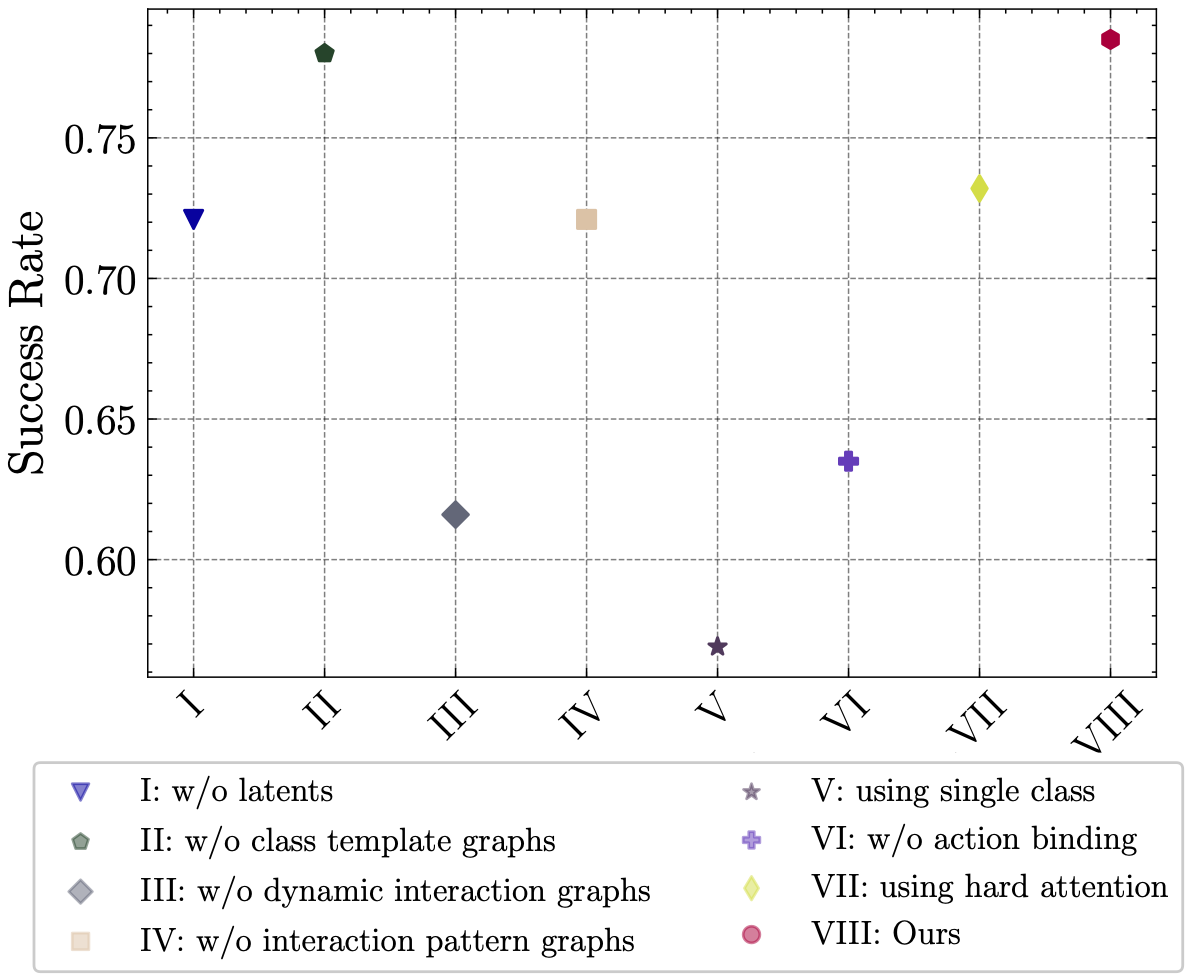
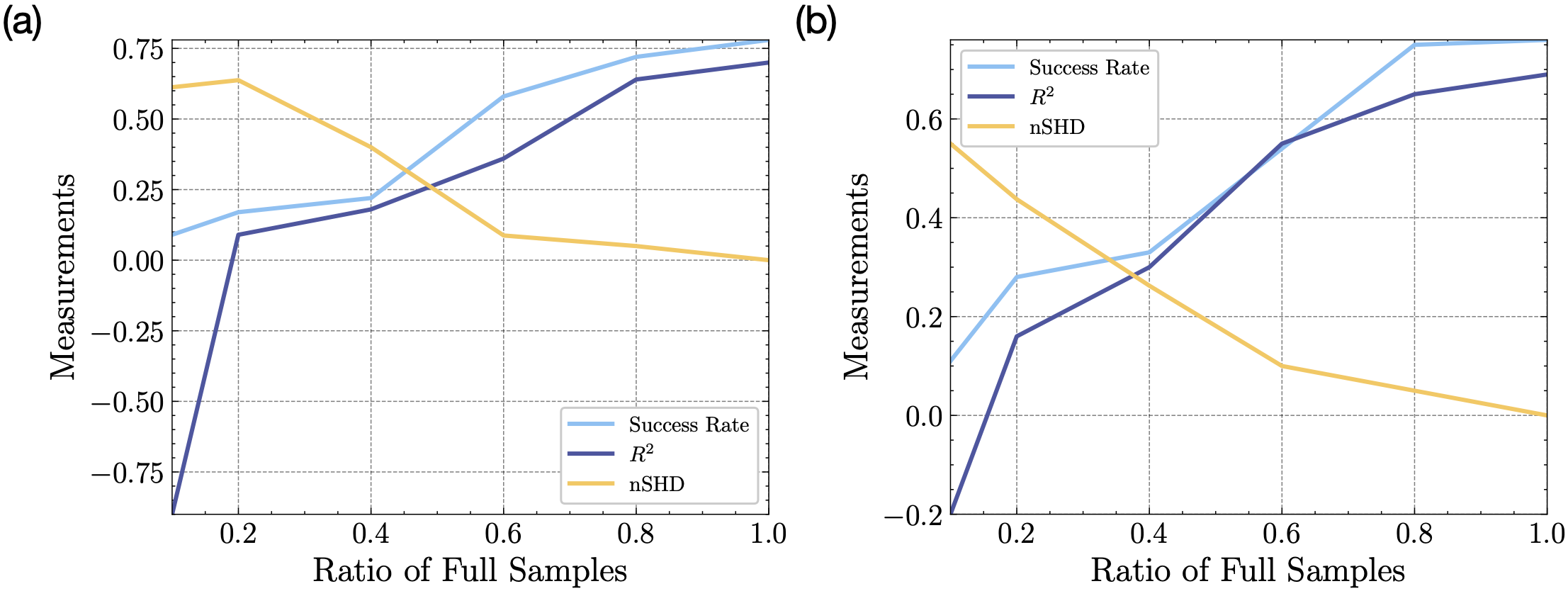
In many reinforcement learning tasks, the agent has to learn to interact with many objects of different types and generalize to unseen combinations and numbers of objects. Often a task is a composition of previously learned tasks (e.g. block stacking). These are examples of compositional generalization, in which we compose object-centric representations to solve complex tasks. Recent works have shown the benefits of object-factored representations and hierarchical abstractions for improving sample efficiency in these settings. On the other hand, these methods do not fully exploit the benefits of factorization in terms of object attributes. In this paper, we address this opportunity and introduce the Dynamic Attribute FacTored RL (DAFT-RL) framework. In DAFT-RL, we leverage object-centric representation learning to extract objects from visual inputs. We learn to classify them in classes and infer their latent parameters. For each class of object, we learn a class template graph that describes how the dynamics and reward of an object of this class factorize according to its attributes. We also learn an interaction pattern graph that describes how objects of different classes interact with each other at the attribute level. Through these graphs and a dynamic interaction graph that models the interactions between objects, we can learn a policy that can then be directly applied in a new environment by just estimating the interactions and latent parameters. We evaluate DAFT-RL in three benchmark datasets and show our framework outperforms the state-of-the-art in generalizing across unseen objects with varying attributes and latent parameters, as well as in the composition of previously learned tasks.